How is hashing speeding up your CDN

Top network infrastructure is a must for fast and reliable content delivery. But it doesn't work on its own. Every requested URL must be evaluated against hundreds of millions of values stored in any chosen data center. And it has to happen fast. We're talking milliseconds. That's when hashing comes into play.
Why hashing?
In recent years, the word "hashing" has become well known even among non-tech people mostly thanks to the growing crypto market. Generally speaking, we use a hash function (#) to map data of arbitrary length to a range defined by a hash function. Bitcoin, for example, checks whether the final hash is less than the difficulty level, making it valid and eligible to add to the chain. [1]
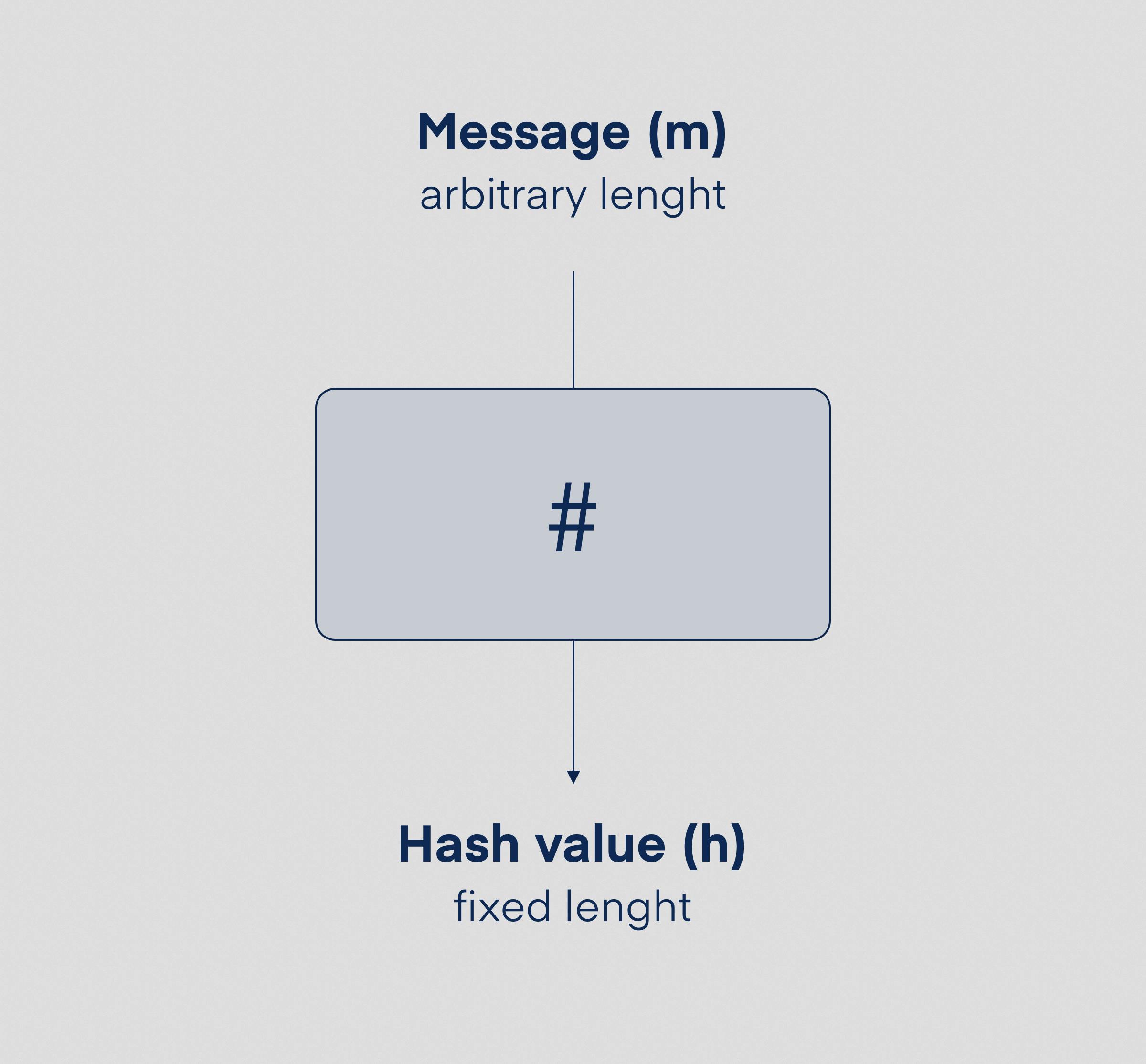
In terms of content delivery, hashing is crucial for increasing the efficiency of various parts of the delivery process. In the example below, we will quickly discover how calculating hashes speeds it up.
Simple CDN algorithm
Imagine you are given the task of building a simple CDN. For simplification, you can ignore all metadata, such as headers, and you are only required to check whether any of the servers have the desired URL in cache or not.
Naive approach
The most naive and obviously wrong approach would be using string matching. You store cached URLs in an array of strings, check for equality, and do that on every server. The complexity of this approach is m x n, where m is the length of string and n is a number of cached URLs on all your servers).
Simple math: This solution quickly becomes infeasible, even with relatively small numbers. The URL to the background image on our homepage https://www.cdn77.com/_next/image?url=%2Fimage%2Fpage%2Fhome%2Fglobe.png&w=3840&q=75 is 84 characters long (m). We need to fetch it from a DC with 100 servers, with each having 10 million files in a cache (n). 84 x 100 x 10 000 000 = 84 000 000 000.
{kind=link}
This means that a single 1GHz processor would take 89 seconds(!) just to find the file in cache. Even if you do it concurrently on all 100 servers, it would take almost a second to serve a single file. With millions of requests every second, it's evident that just throwing more computing power at the problem won't do it. It will waste a lot of computing power only to come up with a lot of "no" answers and maybe one "yes".
Hashing is a way you want to take. Keep in mind that all the examples that I'm about to provide still give you an extremely simplified description of reality, but enough to give you an idea of what happens when a user's request is delivered to one of our PoPs.
Upgrade no. 1: Hashing for lookup
We can upgrade the above approach by storing a hash of the URL instead of its string value. Now, when the server is queried for URL, it will first hash it to an integer and use it as a key. We can then easily search for such a key with logarithmic complexity at worst using a suitable data structure (e.g., AVL or any other balanced tree). That's a significant improvement over the first solution. Instead of m x n, we reduced search time to log(n). But still, doing it on all the servers would be too costly.
Every PoP consists of hundreds of servers, and we can't query them all for the same thing. We need to pick the server before asking it whether it has the URL in a cache.
A constant number of servers?
The most straightforward solution is to number your servers and map those numbers to their IP address. When a request reaches the PoP, you will first hash the URL to an integer and then modulo it by the number of servers (k). The result of key mod k will always be the correct server to ask if it has the requested URL in a cache. This is a well-known load balancing technique.
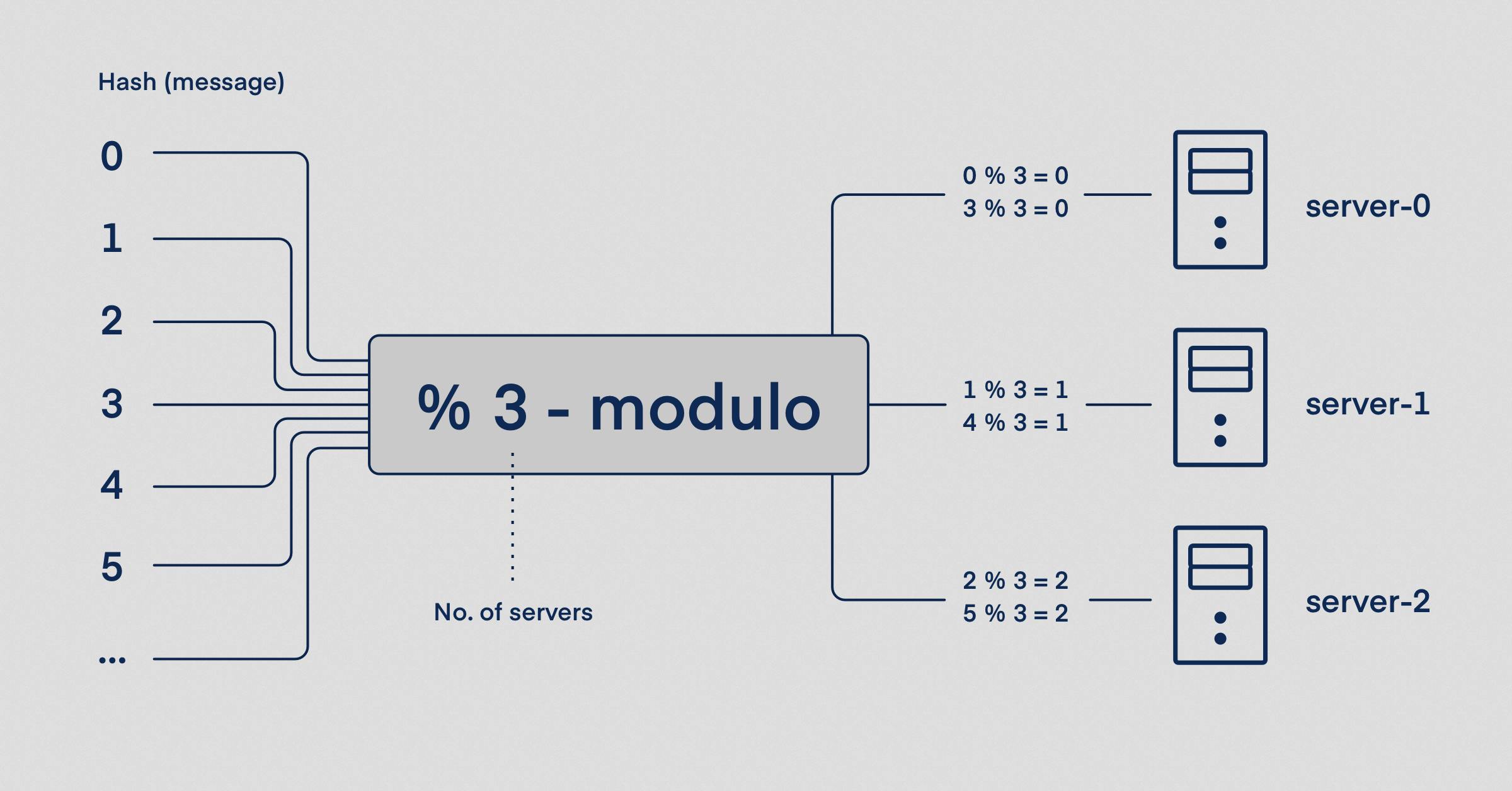
If the number of servers stayed the same, we would be done here. But that is rarely the case. In reality, we often want to scale up and add some servers to the pool or take some down for maintenance. Every time the number of servers changed, every key mod j (new no. of servers) would point to a different server, and the entire cache would effectively be lost. A minor modification will solve that.
Upgrade no. 2: Consistent hashing
Consistent hashing directly addresses the problem of changing the number of servers. Instead of assigning one number to the server, we map them to several (hundreds realistically) unsigned integers, evenly distributed in the unsigned int range (2^32). Conceptually, you can imagine a clock face on which each server appears several times.
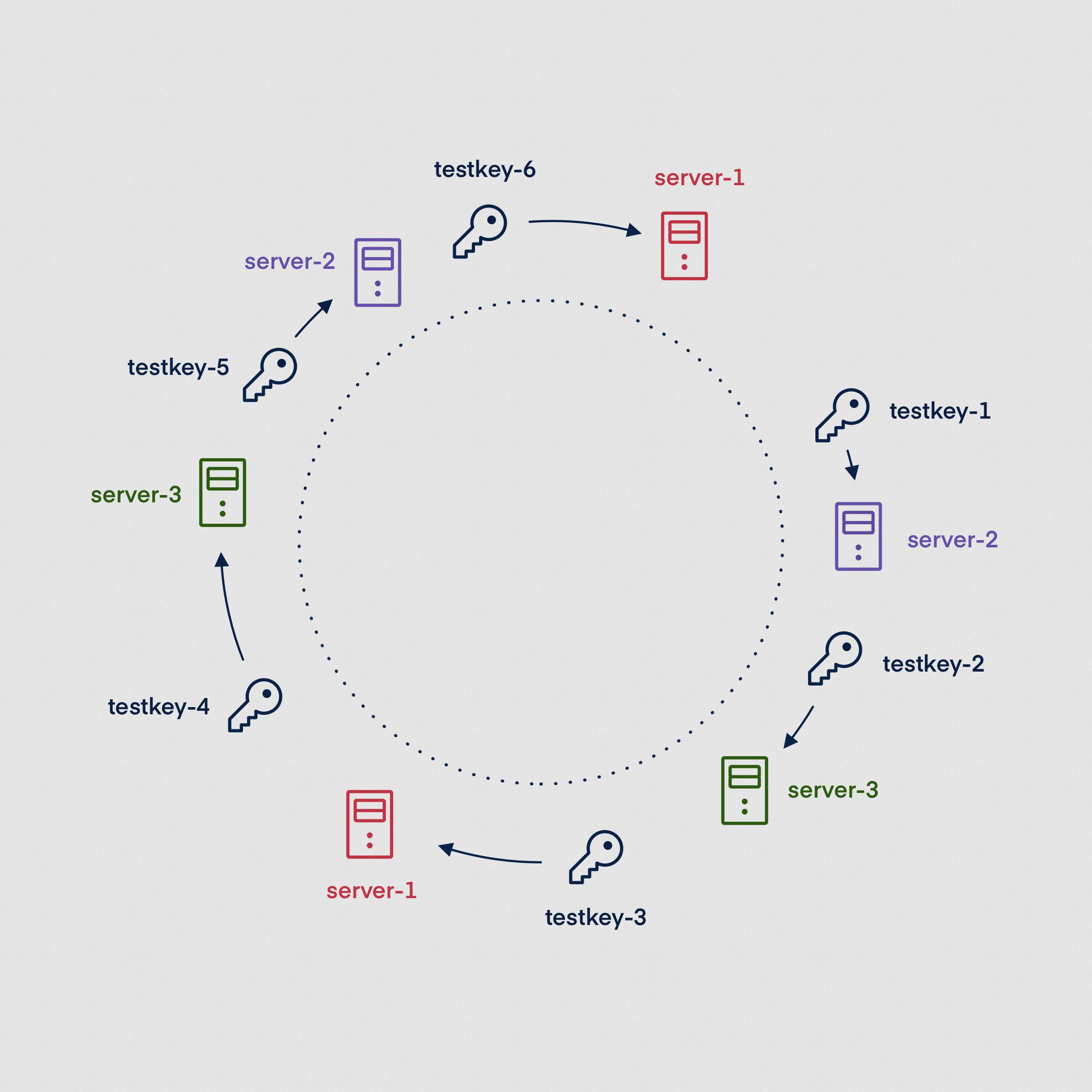
An incoming request for a URL is hashed to a single integer. The next biggest number on the clock is the correct server, which should hold the requested file. If the value of the hash is greater than the biggest number assigned to any server, we choose the first one.
Combining this approach with an appropriate hash function guarantees that only a tiny portion of keys end up pointing to a different server when we add or remove one.
Multilayer cache
Consistent hashing also boosts the performance of a multi-layered setup we have described here (although maybe not so much boosts as makes it possible).
When the request needs to be forwarded to the next layer, we instantly know not only where the next layer is located, but we also know which server exactly should have the requested file in cache. The mechanism is identical to choosing a server inside a single data center.
Why not trie?
Trie, or prefix tree, fits the case of a CDN almost perfectly. Lookup complexity is linear with a length of string, the same as calculating the hash. Unfortunately, they won't help with the second function of hashing, which is choosing the correct server.
That being said, we do use prefix trees and numerous other structures for more complex operations than simple lookups, such as prefix purge.
Conclusion
Even tiny optimizations become noticeable during traffic peaks. Search must be nearly instantaneous, at the rigth location and on the correct server. Sufficient hashing power is helping us do just that.
Milliseconds matter to us, and we are always looking for new ways to improve and speed up one thing or another. Visit our website to learn more about our network and other CDN features.
Resources:
[1] https://blockgeeks.com/guides/what-is-hashing/#The_mining_process

Developer